Lawrence邹旭
Linux动态追踪技术简介
背景
作为一个做系统性能优化的新人,Linux动态追踪技术是帮助我剖析系统性能的重要工具。在学习Linux内核追踪技术的过程中,我花费了很长一段时间阅读了许多书籍、博客和开源项目,从一开始看到Kprobe、Tracepoints、USDT等名词时的不知所云,到搞不清Perf、BCC、BPFTrace等框架和工具之间似有似无的关联关系,一直到现在终于对他们的原理和功能范围有了一个相对清晰的认识。本文我记录了Linux动态追踪技术部分重要技术的基本介绍和以及我的一些思考,希望对想了解Linux动态追踪技术的朋友有所帮助。
历史渊源
Linux操作系统被广泛用于个人PC和企业服务器上。随着Linux操作系统上的软件生态不断扩张,尤其是进入当今云计算场景下,整机上的软件系统变得非常庞大。在这样一个庞大的系统中,出现问题如何调试是一个非常困难的问题。Linux动态追踪技术就是一种能对一台运行中的机器进行稳定性和性能分析和诊断的技术。它在社区贡献者们开发的几种机制下逐渐演化为一套系统化的追踪框架。
下图为Linux动态追踪的历史。图中将Linux动态追踪相关技术分为三个层次:(1)探针,它是基础的数据源;(2)数据源收集机制,它是一套收集数据源数据的框架;(3)前端工具和框架,它是用户程序进行动态追踪的工具或者编写自定义动态追踪工具的编程框架。
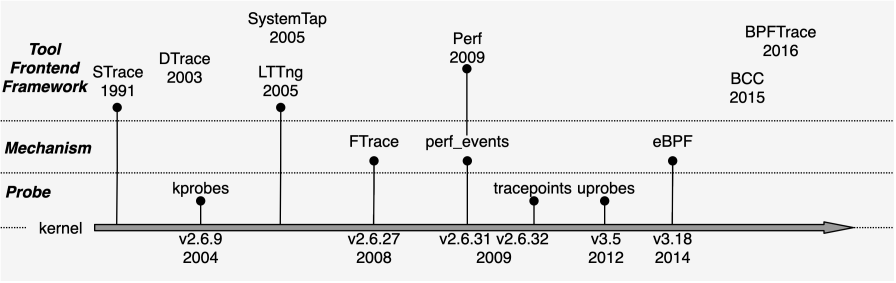
技术名称 发布时间(内核版本) 背景 Kernel主分支是否支持 STrace 1991 Paul Kranemburg为SunOS开发 是 KProbes 2004(v2.6.9) 是 LTTng 2005 Mathieu Desnoyers个人开发 是 DTrace 2005 最早2003年可用,Sun公司发布 否 SystemTap 2005 Red Hat, IBM,Intel,Hitachi,Oracal等共同贡献 是 tracepoint 2009(v2.6.32) Steven Rostedt等共同开发 是 FTrace 2008(v2.6.27) Steven Rostedt等共同开发 是 Perf/perf_events 2009(v2.6.31) 是 uprobe 2012(v3.5) 是 eBPF 2014(v3.18) 是 BCC 2015 Brenden Blanco发起 是 BPFTrace 2016 Alastair Robertson发起 是
初看上去,这些机制比较杂乱,尤其是上层的前端工具,互相有区别但功能上又有很大的交集。这是因为Linux包含的这些追踪机制本就不是按照一个整体统一设计出来的,是在演化过程中慢慢出现的。不同的框架都有自己一套使用和操作数据源的方法,他们各自有自身适合的使用场景。 在介绍Linux动态追踪之前,先介绍两个工具STrace和DTrace。STrace是早期动态追踪工具的代表,他方便简单但是功能有局限性。DTrace则是著名的动态追踪框架,它并非Linux平台的,但Linux在过去很多年都一直追求有一套和DTrace一样功能强大的动态追踪工具。
STrace
STrace是内核里用于追踪系统调用的小工具,它已经有非常久远的历史了,可以算是早期系统追踪的一个很好的例子。它在调试系统软件,帮助用户根据系统调用过程理解软件执行行为非常有帮助。 STrace通过调用ptrace系统调用跟踪程序的运行实现。当STrace跟踪一个程序时会产生两个进程,一个是跟踪者STrace,一个是被跟踪者,即被追踪的程序。它通过ptrace系统调用使得被跟踪者在每次调用一个syscall的开始和结束时通知父进程,父进程则在syscall执行的开始和结束记录下系统调用号、参数和返回值。这样,子进程结束后父进程便获取到了所有的系统调用信息。
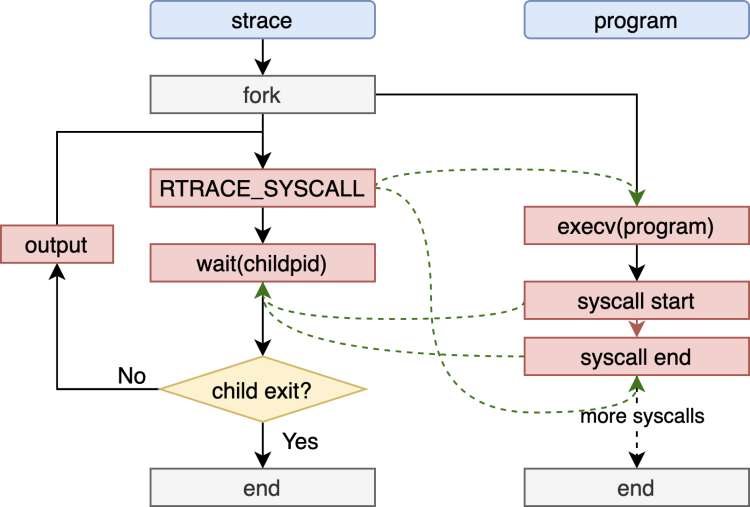
可以看到,STrace其实就是针对系统调用的一种定制化的动态追踪工具。它非常轻巧和方便,但是它的缺点也很明显:(1)每次系统调用时需要通知父进程处理,单次处理需要进行进程切换,开销很大;(2)高频率的系统调用会大大降低程序运行性能,因为进程的切换次数取决于系统调用的次数。因此,STrace适合于做简单的调试,但对性能的影响风险太高,不太适合线上环境使用。
站在动态追踪的角度,STrace只能在系统调用追踪这一小块空间发挥作用,而整个操作系统是庞大的。因此,一个能扩展至整个系统的框架性的工具成为需求。Dtrace就是这样一个工具。
参考
strace Wow Much Syscall:https://www.brendangregg.com/blog/2014-05-11/strace-wow-much-syscall.html wiki: https://en.wikipedia.org/wiki/Strace
Dtrace
DTrace(Dynamic Tracing,动态追踪)是由Sun公司开发的一款用于定位系统性能瓶颈和调试系统错误的工具。可惜的是Dtrace没有Linux版本,和Dtrace同时代的Linux上一个类似的工具是Systemtap。Systemtap提供一套语言,允许用户编程,然后它将程序翻译成C语言并编译成内核模块进行执行。因此,Systemtap功能上来说是非常强大的,功能广度上胜过了后来的bpftrace。Systemtap和Dtrace相比易用性太差,它依赖多,且新人编写程序很容易造成内核panic,而Dtrace则是一个开箱即用的工具。从DTrace可以总结出一套动态追踪框架大致需要有具备以下三个特征:
(1)遍布于内核态和用户态程序的大量探针。他们就像系统软件中的摄像头一样,分布在各个关键路径上,并且只有在需要使用时才打开。张亦春有一个观点非常形象,动态追踪把系统看成一个数据库,我们可以从这个数据库中查询大量我们需要的数据。这些探针就是我们的数据源。
(2)安全的探针程序执行环境。正如公路上的摄像头不应改变车辆的行驶轨迹一样,动态追踪只是追踪,不应该修改程序的运行轨迹。动态追踪的安全执行可以通过将程序编译成中间码,并做正确性验证来保证,Dtrace以及BPF都是这么做的。
(3)一套用于操作探针的编程语言和配套的编译环境。编程语言的引入就将动态追踪从一些像STrace一样“写死”的工具扩展成按需设计工具了。这样开发动态追踪工具不再是内核开发者等少数开发者才能完成的事情,而是任何一名系统软件开发人员都可以编写自己的工具了。
就是这样一些特征,Linux系统在Dtrace诞生后很多年都没有一套可以与之媲美的工具。后来,随着BPF的出现和各种Feature逐渐支持完整,Linux终于具备了一套强大的底层探针底座,这时的BPF被Branden Gregg称为Linux上的DTrace。此后,Linux也具备有一套遍布于内核态和用户态的探针了,社区开发者们基于BPF开发了BCC和BPFTrace两大前端工具,这样Linux上的动态追踪系统基本成型,普通开发者也能编出功能强劲的性能分析工具。
参考
Dynamic Instrumentation of Production Systems:https://www.cs.princeton.edu/courses/archive/fall05/cos518/papers/dtrace.pdf
Comparing SystemTap and bpftrace:https://lwn.net/Articles/852112/
系统观测底座-各类探针
性能分析领域有个词叫做Observability(观测力),英文解释是“the ability to observe”,它描述的是系统能被观测的程度。为了理解Linux动态追踪技术所具有的Observability,我们需要从理解数据源的工作原理开始,摸清系统观测底座的能力范围。
kprobes
kprobes是一种可以在内核任意位置插桩的动态追踪技术,他在调试和性能信息的获取上发挥着重要作用。kprobe的实现基于中断机制,通过在探测位置埋入中断指令来触发中断,在中断处理的过程中执行用户指定的钩子函数。这一基于中断调用钩子函数的方法也用在uprobes中,另由于USDT也可基于uprobes实现,所以该方法也被用在USDT的实现中。linux中最早的kprobes由Andrew Morton引入,当时仅支持i386。下面以x86架构为例,简要分析kprobe的工作原理:
-
用户程序构造好kprobe(指定好探测地址和钩子函数)并注册。注册过程中,内核将探测地址处的部分指令字节(一般为单条指令最大的可能长度,以保证后面的单步执行时至少有一条指令可执行)保存到kprobe结构体中的一个域(insn),并将探测地址处指令字节改为INT 3中断指令(该指令仅一个字节,即0xcc)。
-
内核程序执行到探测地址时触发INT 3中断,设计好的中断处理函数中会触发kprobe_exceptions_notify函数的调用,该函数会根据中断号调用指定的kprobes相关的处理功能。
-
对于INT 3中断,kprobes的处理流程为先执行pre_hander,再设置单步执行,执行第1步中拷贝的原内核程序指令。根据单步执行的规则,执行一条指令后会自动触发INT中断,这样又会进入到kprobe_exceptions_notify中。此时该函数根据中断号判断推出中断原因为DEBUG,然后调用post_handler函数。这样,kprobes通过区分中断号来判断是单步指定执行前还是执行后来调用不同的handler函数。
-
注销kprobe,恢复内核程序环境。
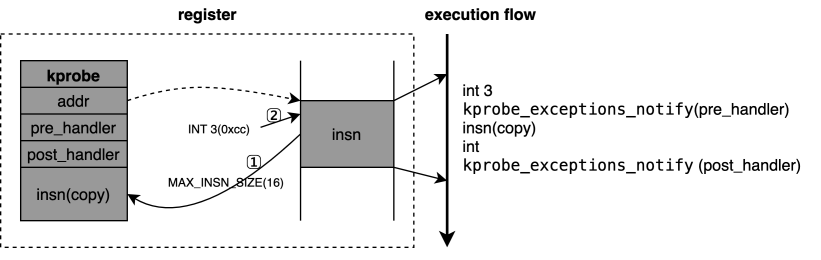
功能方面,除了do_int3等个别特殊函数外(因kprobe本身会借助于INT 3中断,插桩在do_int3中会造成死循环),kprobe可以获取内核中几乎所有函数的信息。
性能方面,从执行流可以看出,每次kprobe探测点的执行要多出两个中断处理过程再加用户程序注册的函数。实际上,在不带post_handler的kprobe中,图中的INT 3指令被优化成一条JMP执行,内核程序可不通过中断直接执行pre_handler。只用pre_handler的kprobe,用户程序的钩子函数是性能负载的主要因素。
安全性方面,kprobes并不是一种比较稳定的技术。首先,他依赖于地址(可能通过函数标签间接指定或者直接指定),这意味着在内核版本更新的时候,这些地址的改变或者函数名的改变都可能造成原来的kprobes程序不能执行或者执行错误。另外,由于kprobe会关闭抢占,也可能关闭中断(视架构而定),因此对一些可能造成程序睡眠的函数的调用可能导致机器宕机。
参考
kernel commit:4ece58992befbbbc83f27a7c92a0353bdff1e3b6
uprobes
uprobes在用户态和内核态的kprobe对应,能实现在函数入口、特定偏移处以及函数返回处进行插桩。它的实现比kprobes稍微复杂一些,其内部的插桩原理和kprobe是一样的。它与用户态的接口有两种方式:(1)通过伪文件系统实现,使用/sys/kernel/debug/tracing/下的uprobe_events控制某个uprobes的开发和关闭;(2)perf_event_open()系统调用。这两个API最后调用了内核中的register_uprobe_event()函数。该函数注册uprobe,它包含了注册的可执行文件和偏移等信息。当可执行文件执行时,它首先被装载进内存中时,此时内核会根据uprobe注册信息将对应的地址替换成断点指令,从而触发uprobe的中断处理流程uprobe_exception_notify。
在功能、性能、安全性方面的特点来讲,uprobes和kprobe非常相似。除了这些外,维护负担也是需要考虑的一大问题。由于用户程序的改动更加频繁,uprobes的插桩点相对于内核probe来说更加不“稳定”,维护成本更高。由于uprobes追踪的是用户程序,开发者可以提前在应用程序中添加常用静态桩(即后文的USDT),这对于性能监控和调试来说不仅方便而且维护成本更低。
参考
kernel commit:654443e20dfc0617231f28a07c96a979ee1a0239。
tracepoints
tracepoints是一种静态追踪工具,他需要在内核编译前设置好,编译后便无法进行修改了。相对于kprobe,tracepoints要稳定的多,它被写好在指定的函数中,只要该函数在,内核的跟新不会导致tracepoints的失效。在tracepoints的处理函数中,传入的参数是给定的,这也避免了用户程序尝试通过ABI对一些变量进行访问可能造成的错误。不过tracepoints能实现的功能,kprobe也能实现。我把tracepoints看作是定制化的内核探针,它不会像kprobe一样随着函数名的改变或者函数地址的改变而失效,这也是为什么既然有了kprobes,tracepoints并不多余。
-
tracepoint是一个带有probe函数的结构。
-
内核中静态指定好若干tracepoint,比如放在一个函数的结尾,并且可传入事先规定好的参数。
-
用户程序通过register_trace_xxx函数注册一个probe函数,该probe函数里完成用户需要的功能。
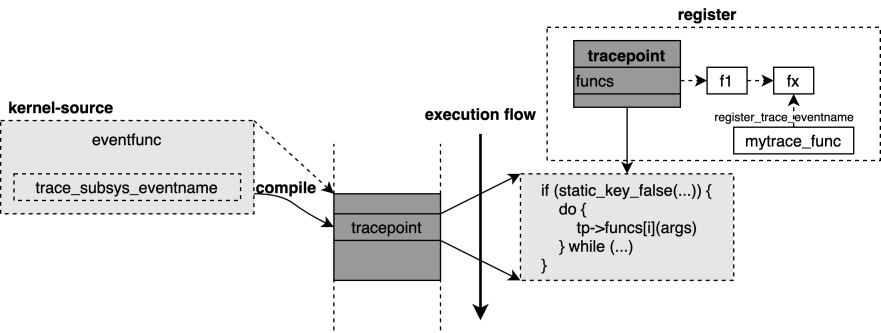
tracepoints在性能和安全性方面都比kprobe表现出色,根据内核中samples/bpf/test_overhead下的测试,它在性能上比kprobe大约高效20%。
参考
bpf, tracing: introduce bpf raw tracepoints:https://lwn.net/Articles/748352/
USDT
USDT即(user-level statically defined tracing)用户态预定义静态跟踪,它是用户态下的tracepoints。USDT在用户程序的关键位置留下插桩点,用于对程序进行调试、性能观测等功能。USDT探针在关闭时就是一条nop指令,基本不影响程序性能。目前linux上我们可以通过引入systemtap提供的sys/sdt.h书写带USDT探针的c程序;此外还有libstapsdt作为运行库给动态语言动态地添加USDT探针,即不需要提前在程序代码中添加好探针。
通过sys/sdt.h实现的USDT probe信息在程序被编译后保存在ELF文件的.note.stapstd section,而probe对应的地址指令为nop。当程序被USDT工具装载执行时,该工具根据.note.stapstd中对应的probe信息将nop指令换成int3指令(X86下),后面的执行就和uprobe一样的。从这里可以看出,USDT工具的底层插桩的实现一般是基于uprobe的。
参考
Exploring USDT Probes on Linux:https://leezhenghui.github.io/linux/2019/03/05/exploring-usdt-on-linux.html
pmu
pmu和前面几种数据源有很大不同,pmu是一种硬件机制,并且它是为性能而生的。pmu(Performance Monitoring Unit),即性能监控单元。pmu用于统计系统中发生的特定硬件事件,例如缓存未命中(Cache Miss)或者分支预测错误(Branch Misprediction)等。
pmu一方面用以作为硬件事件的计数,起到监控CPU硬件性能参数的作用。除此之外,他还有另外一个重要的作用就是采样。采样即某个事件发生多少次记录一下某些特定数据,这个事件可以是软件上的,比如访问10次IO采样一次调研栈。软件采样的方式一般局限性比较大,比如没有探针的位置无法采样,采样计数开销大等。硬件采样比如根据时钟进行采样则计数非常均匀且在非取样时间段对性能基本无影响。
数据加工与传递-用户接口
有了数据源后,他们如何被用户所用,这就是内核中收集和加工数据源框架所要完成的功能。这些框架间的关系非常“混乱”,“混乱”体现在他们的功能间存在很大的交集。这种复杂的关系向上也反应在前端工具上,比如BCC利用perf_events,但是perf也支持运行BPF程序。他们仿佛互相交织在一起,只有看内核提交历史才能捋清楚怎么发展成现在这样的。
这里引用https://mmi.hatenablog.com/entry/2018/03/04/052249中一张图来展示他们之间的关系,这就非常清楚了。通过理解这些框架的结构,我们可以理解到他们为什么不能完全互相替换,各自依然有存在的理由。
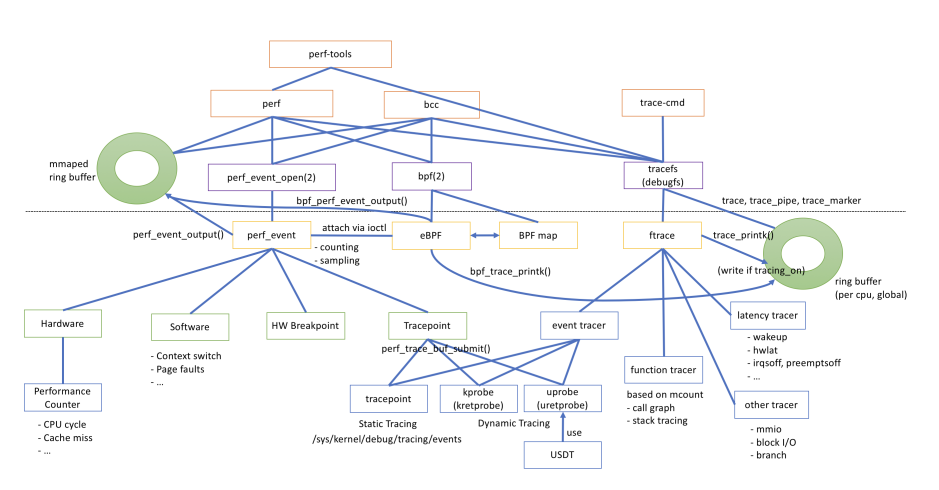
ftrace
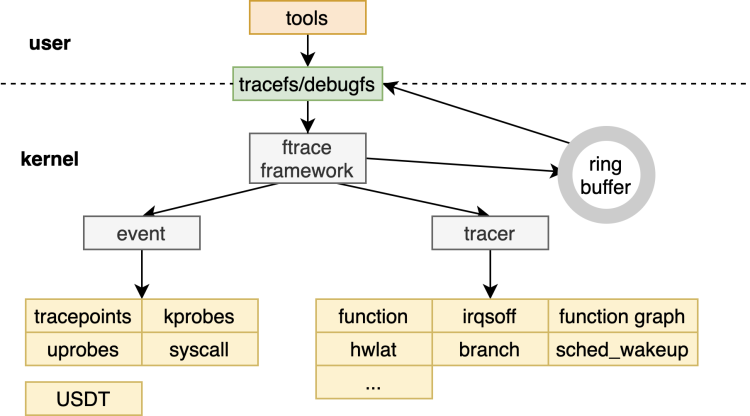
ftrace是Function Tracer(函数追踪)的意思。由名字可知,ftrace最早用于记录内核在运行时的各种函数调用信息。随着追踪功能的不断增加,ftrace上扩展出了越来越多的tracer插件,从而使得ftrace成为一套动态追踪的框架。ftrace包含一下几个部分:ftrace框架核心,ring buffer,debugfs,event和各种tracer。值得注意的有两点:
(1)ftrace本身不是工具,而是通过debugfs接口与用户进行交互。原始的ftrace使用方式是读写debugfs下的对应文件以控制和观测各种event/tracer的打开和关闭。它有两个使用比较广的前端工具trace-cmd和KernelShark。
(2)event和tracer属于ftrace下的两大类trace。event源于trace event,tracer源于function tracer。他们的区别是内核里的实现方式不同:
a. trace event原来只有Tracepoint,用的是静态插桩,后来加入kprobe也支持动态插桩了,每个插桩点可以单独控制。
b. tracer则是使用类似于Tracepoint的静态写好在内核函数里的void _mcount(void)函数进行插桩,不用时为nop指令。它和Tracepoint区别就在于它不能单独使能,一但使能所有的(数以万计)函数都要插桩,后来为了避免开销过高的问题,引入了filter机制,从而可以实现只对指定的一批函数进行插桩。
我这里根据4.19版本内核画了一张ftrace的框架图,这两类trace的区别用户本身不必关心,可以当成ftrace的tracer。
perf_events
perf_events最初是用来操作PMU硬件计数器的。它有两大功能:计数(count)和采样(sample)。计数只记录event发生的次数,比如TLB miss次数,系统调用次数等;sample则是当某个事件的发生的次数到一个周期时进行采样,记录下大量的信息。sample功能相当于在ftrace的数据采集基础上增加PMU的采样功能,从而有更好的数据分析能力。
perf_events的events是比较容易理解的,比如:Hardware events实际上封装了PMU的count功能;Software events的实现和tracpoints一样,静态埋点似乎都是类似的;而Tracepoint则完全是复用了ftrace的插桩点。perf_events比较重要的特点是它的组织方式,它可以按照cpu和task维度进行组织。如果按照CPU维度进行组织,只要对应的CPU处于online状态它就处于激活状态;如果按照task进行组织,只有该perf_events所属的task在运行时才能被激活。
BPF
BPF最早用于监控系统网络,并且用户可以使用自定义的程序来分析网络数据包。但是早期的BPF程序的使用方式受限,用户只能借助少数的几个用户空间程序使用BPF,比如Tcpdump和Seccomp。BPF中很重要的一点是在内核中引入了一个专门执行BPF程序的虚拟机,这为后来BPF程序的安全性和高效率奠定了基础。后来,eBPF的出现扩展BPF原有的指令集,并提供了bpf系统调用用于用户空间和内核之间的交互,进一步将BPF程序的使用方式推广到普通用户程序。
以下借用Brendan Gregg的一张图展示BPF的工作流程:
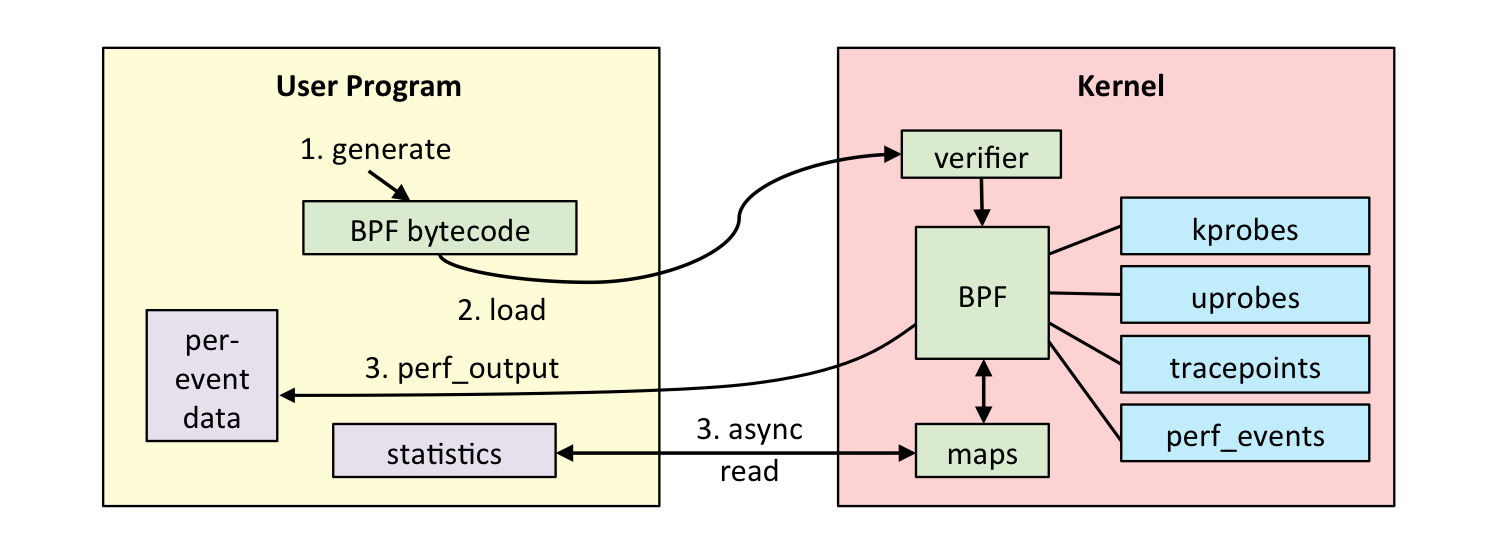
BPF的用途出了原来的网络分析,进一步被用于动态追踪是非常自然的。因为它太符合DTrace这样的动态追踪框架的结构了:丰富的探针源、安全的执行环境、配套的使用语言(BPF接口是针对C语言设计的)。它相对于perf_events和ftrace的优势至少有两点:
(1)方便用户编程的接口。BPF只有一个系统调用bpf,但它提供了各类event的插桩方法,包含perf ring buffer、BPF MAP、trace ring buffer三种数据通道的交互方式。后来BCC、bpftrace的引入更进一步完善了BPF生态。
(2)更安全的运行环境。所有的BPF C程序先被编译为BPF二进制码,然后在装载进内核时先通过验证器进行验证,保证正确性。在确保BPF程序安全的情况下,才会通过虚拟机或者JIT的方式得到运行。
前端工具与编程框架-方便易用
内核里的各种收集数据源数据的框架对普通用户来说不太友好,他们被进一步封装为方便用户使用的用户态前端工具或者可编程框架。这些框架各有特点,用户需要熟悉他们的特点并根据使用场景选择合适的工具。
perf
perf是一个以计数和采样功能为主的主打性能分析的工具,后来也通过bpf系统调用支持运行BPF程序,不过不如BCC方便。perf通过通过perf_event_open控制perf_events,可以看作是perf_events多功能前端工具。因此,它的功能和perf_events一样,包括计数和采样两部分。由于perf在CPU的性能数据分析方面有很多定义良好的功能,使用起来非常便捷,因此依然在Linux上应用广泛。
Brendan Gregg利用perf的采样功能发明了新的可视化方式-火焰图。火焰图以直观的图片形式反映了系统中各个函数的性能负载分布比例。这也迎来了perf的高光时刻。事实上,perf的这种调用栈分析功能是系统软件的全栈分析方式。普通的工具,比如runqlatency、numastat是专门为系统中的某个子模块定制的,只能分析局部的性能。而基于函数调用栈的采样分析方式则突破软件本身模块的限制,推广到了资源和任意使用者的关系上来。
参考
perf Examples:https://www.brendangregg.com/perf.html
BCC
在BCC之前,编写eBPF程序是比较复杂的。一个简单指标的采集使用纯C代码书写需要两部分:一个BPF C程序,用于装载进内核中的插桩点进行事件处理;一个用户态程序用于BPF C程序的装载和对其输出的格式化打印。这一过程过程中的很多操作可以借助libbpf提供的API来方便实现。这种方式使用BPF程序的优点是依赖少,但是编译环境的搭建比较繁琐,而且BPF程序是经常会修改的,每次修改都要重新编译。
BCC是一套用于开发BPF程序的高级编程框架,它使用clang作为编译器,支持使用C、Python等多种高级语言。现代的BCC基于libbcc和libbpf,但实际上BCC诞生在这两个库之前。BCC还包含了70多个工具,这些小工具在系统的各个部分提供了观测性,这是BCC生态的重要一部分。
BCC比libbpf方便许多,比如设置perf_events的频率、取样周期,有直接的封装接口,而libbpf需要直接设置perf_event_attr结构。纯C的写法非常麻烦,实现一个简单的功能需要很多代码。BCC抽象了用户的接口,提供了更高层、方便的编程机制。
使用BCC的工具在执行时候是动态编译的,每次运行自动编译。而且每次编译,BCC采用动态编译的方式使用BPF C程序在我看来至少有两个好处:(1)eBPF的filter机制;(2)BPF程序的移植问题。filter在支持全局变量后得到解决。移植问题在BTF之后得到解决。
参考
BPF可移植性和CO-RE:http://arthurchiao.art/blog/bpf-portability-and-co-re-zh/
bpftrace
BCC的使用依然不简单,我们至少需要掌握BCC编程接口和一门高级语言以及对内核有所了解。实际上,BPF程序的数据源相似度很高,使用起来规律性很强,这个特点使得它可以被进一步包装。bpftrace将BPF的便捷性提升到极致,使用它可以使用one-Liner工具。这让BPF的使用方式如果shell脚本一般方便。代码量越少越不容易犯错,其编写难度比用C写方便很多。 但是bpftrace的便捷性并不能覆盖BCC的价值,也无法覆盖纯C书写BPF程序的价值。他们有各自的特点:
(1)bpftrace适用于单行的命令行,用于一次性的问题查询和诊断。
(2)BCC适用于写带命令行的工具,或者写带有指定语言的agent。比如ebpf_exporter是一个调用BPF程序的监控,它就是使用的BCC。
(3)纯C的写法在对依赖库、开销方面有追求时非常有优势。BCC和bpftrace依赖clang编译环境、libbcc、libbpf、kernel-devel等,会给文件系统带来约100M的消耗。
参考
A thorough introduction to bpftrace:https://www.brendangregg.com/blog/2019-08-19/bpftrace.html
bpftrace internal:https://github.com/iovisor/bpftrace/blob/master/docs/internals_development.md
总结
Linux动态追踪技术发展到现在,以及成为了一门积累很深的技术了。每一中追踪方式包含了大量的技术细节,本文只介绍了它比较基础的一部分。并且本文只简要解答了这些技术是什么,而这些技术怎么用、如何结合到性能分析的方法论中去等问题又有很多内容可以拓展。性能分析方面的专家Brendan Gregg在他的个人博客中写作了大量的文章来介绍Linux动态追踪技术的方方面面,我在学习的过程中感叹每套分析方案、每个小工具被打磨的精巧程度,只能感叹他二十年功力实在高深。但是性能分析领域依然有很多问题需要解决,比如如何让性能分析工具更加系统化工作而不是散落在各个小模块上,这依赖于对Linux追踪技术更巧妙的使用。